
# Best practices
This eBook is intended to show you the most popular design patterns and practices related to microservices. I strongly recommend you to track the father of the micro services approach - Sam Newman. You should check out websites like http://microservices.io, https://github.com/mfornos/awesome-microservices and https://dzone.com/ (under the "microservices"” keyword). They provide a condensed dose of knowledge about core microservice patterns, decomposition methods, deployment patterns, communication styles, data management and much more…
# Create a Separate Database for Each Service
Sharing the same data structures between services can be difficult - particularly in environments where separate teams manage each microservice. Conflicts and surprising changes are not what you’re aiming for with a distributed approach.
Breaking apart the data can make information management more complicated;the individual storage systems can easily de-sync or become inconsistent. You need to add a tool that performs master data management. While operating in the background, it must eventually find and fix inconsistencies. One of the patterns for such synchronization is Event Sourcing. This pattern can help you with such situations by providing you with a reliable history log of all data changes that can be rolled back and forth. Eventual Consistency and CAP theorem are fundamentals that must be considered during the design phase.
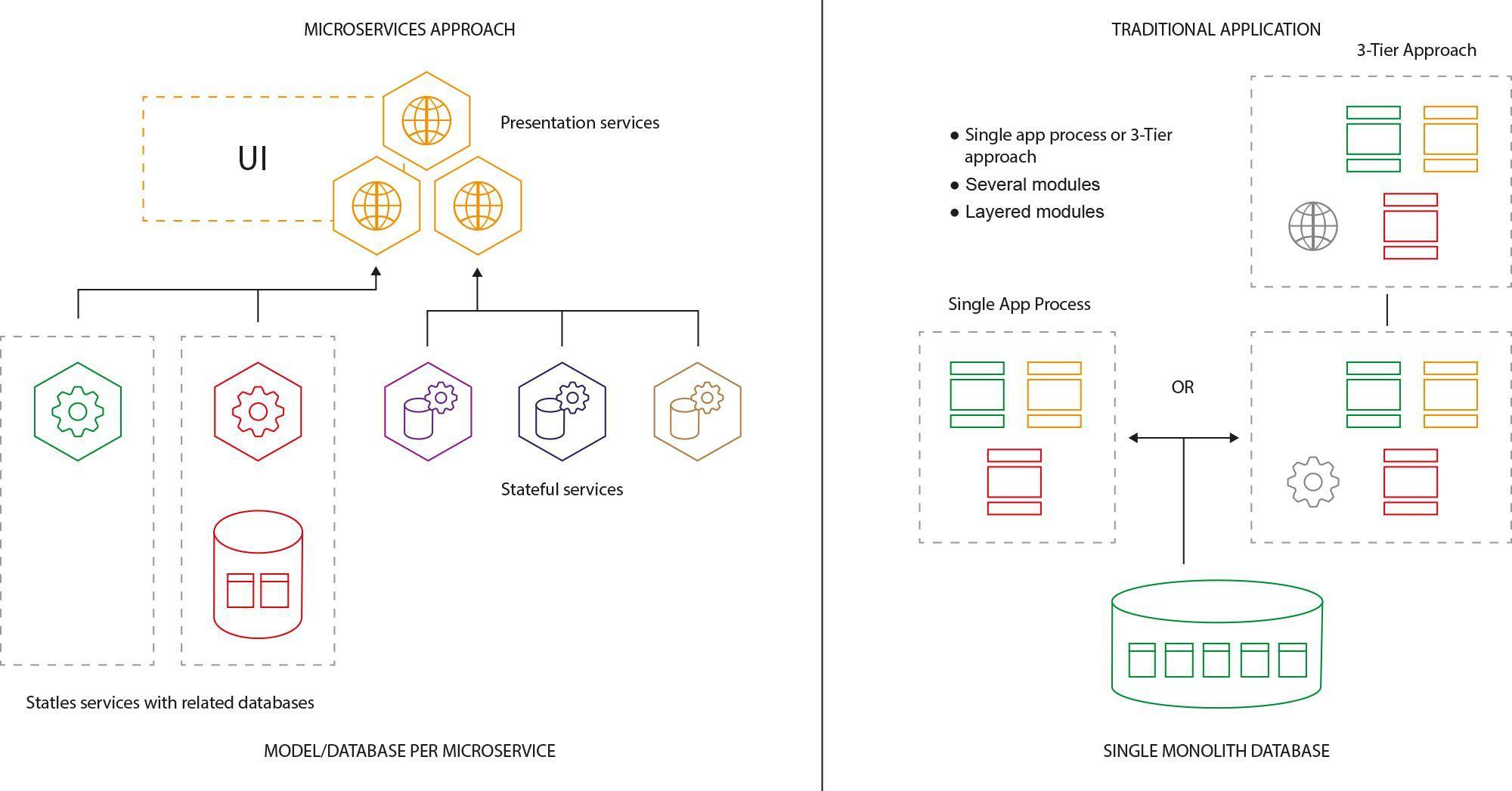
Fig. 4: Each microservice should have a separate database and be as self-sufficient as it can. From a design point of view - it’s the simplest way to avoid conflicts. Remember - different teams are working on different parts of the application. Having a common database is like having a single point of failure with all conflicting changes deployed simultaneously between services.
# Rely on Contracts Between Services
Keep all codes at a similar level of maturity and stability. When you have to modify the behavior of a currently deployed (and stable) microservice, it’s usually better to put the new logic into a new, separate service. It’s sometimes called "immutable architecture".
Another point here is that you should maintain similar, specific requirements for all microservices like data formats, enumerating return values and describing error handling.
Microservices should comply with SRP (Single Responsibility Principle) and LSP (Liskov Substitution Principle).
# Deploy in Containers
Deploying microservices in containers is important because it means you need just one tool to deploy everything. As long as the microservice is in a container, the tool knows how to deploy it. It doesn’t matter what the container is. That said, Docker seems to have become the de facto standard for containers very quickly.
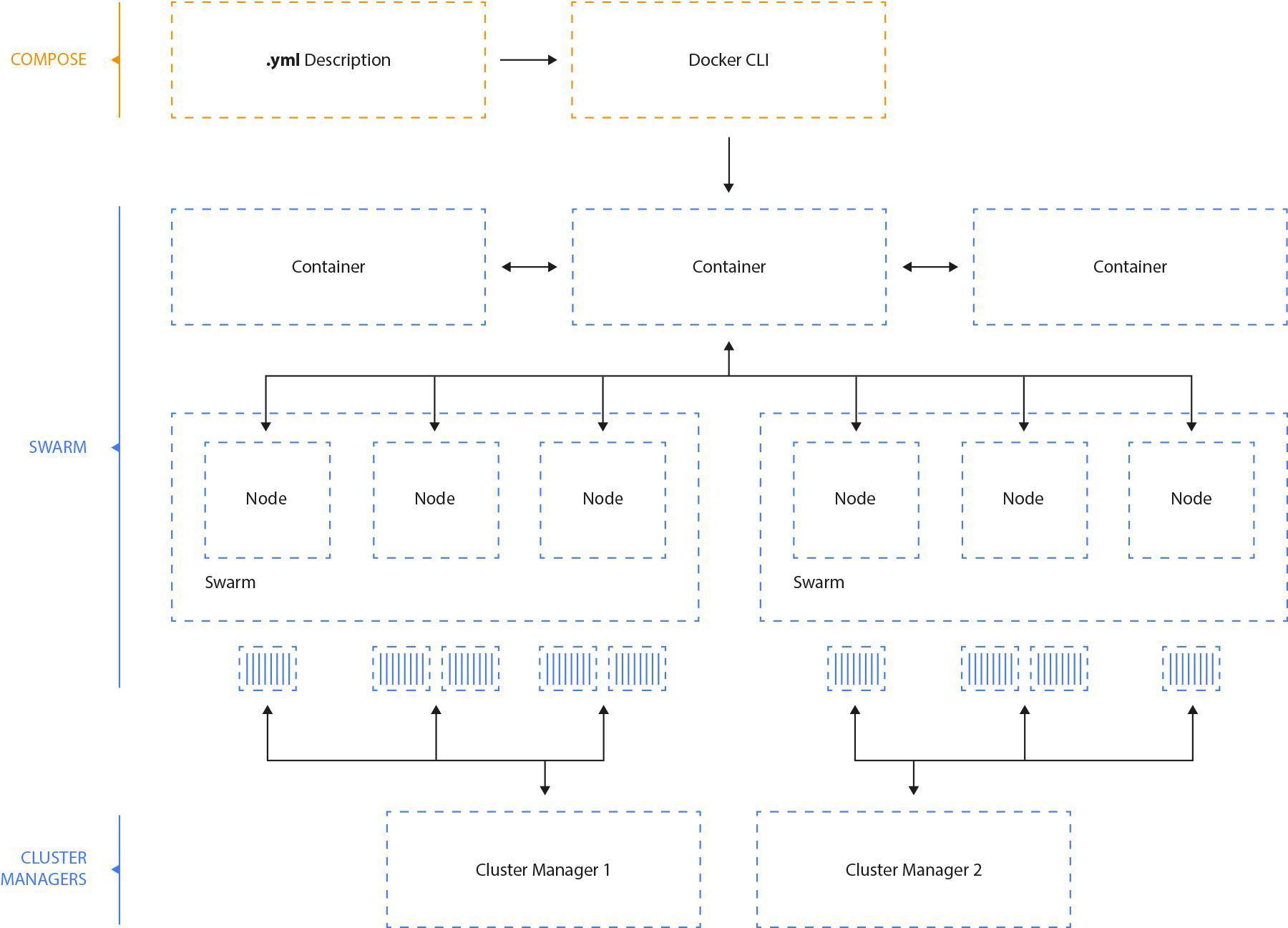
Fig. 5: Source - Docker Blog. Docker Swarm manages the whole server cluster - automatically deploying new machines with additional instances for scalability and high availability. Of course it can be deployed on popular cloud environments like Amazon*.*
# Treat Servers as Volatile
Treat servers, particularly those that run customer-facing code, as interchangeable members of a group. It’s the only way to successfully use the cloud’s "auto-scaling" feature.
They all perform the same function, so you don’t need to be concerned with them individually. The role configuration across servers must be aligned and the deployment process should be fully automated.
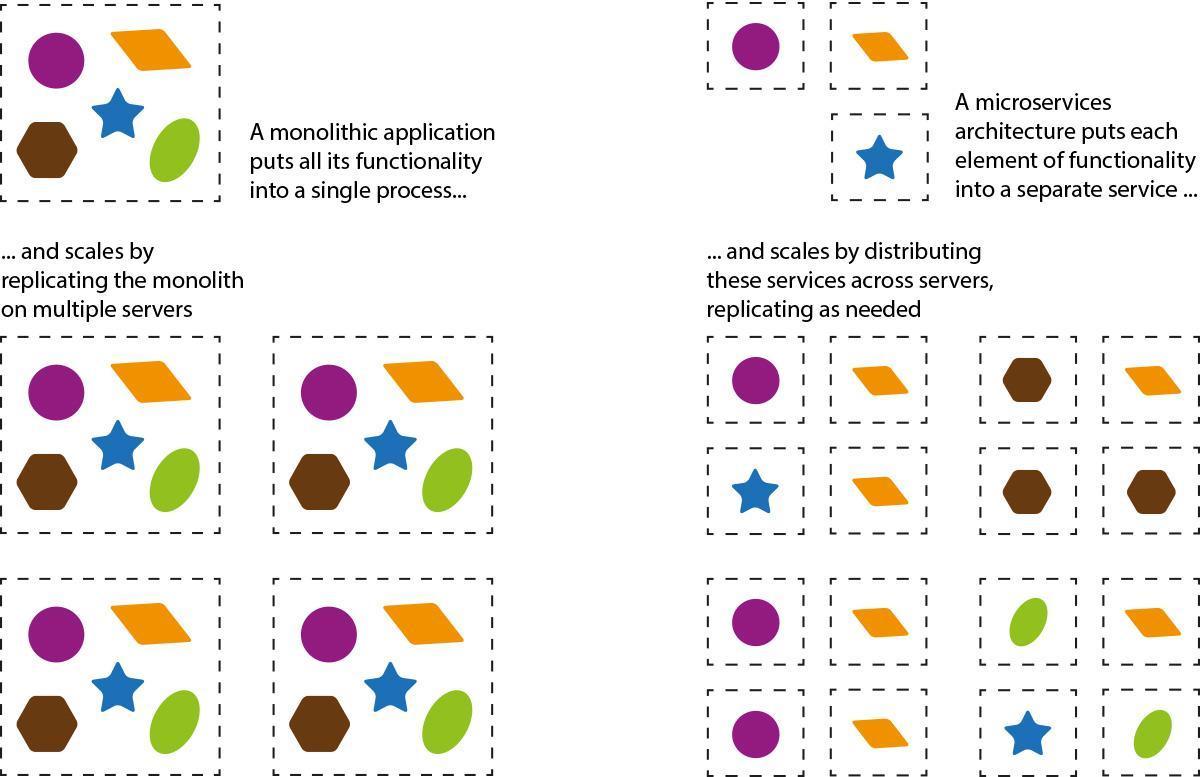
Fig. 6: Original idea - Martin Fowler (https://martinfowler.com/articles/microservices.html). Scaling microservices can be efficient because you can add resources directly where needed. You don’t have to deal with storage replication, sticky sessions and all that kind of stuff because services are stateless and loosely-coupled by design.